Microservices Design Principles: Build Resilient Apps in 2025
Learn the essential microservices design principles to create scalable, maintainable applications. Discover key concepts like decentralized data and API-first design.

Building Future-Proof Applications with Microservices
Want to build scalable and resilient applications? This listicle presents seven essential microservices design principles to guide you. Learn how applying these core concepts, from the Single Responsibility Principle to Design for Observability, helps create robust and maintainable systems. Mastering these microservices design principles empowers you to develop flexible, future-proof applications ready for growth and change. We'll cover: Single Responsibility Principle, Decentralized Data Management, API-First Design, Autonomous Teams, Infrastructure Automation, Resilience and Fault Tolerance, and Design for Observability.
1. Single Responsibility Principle
The Single Responsibility Principle (SRP) is a cornerstone of good microservices design. Applied to this architectural style, it dictates that each microservice should own a single, well-defined piece of the application's overall functionality, minimizing overlap with other services. This principle, derived from Robert C. Martin's SOLID principles for object-oriented design, emphasizes building services with high cohesion (elements within a service are closely related) and loose coupling (minimal dependencies between services). In a microservices architecture, adhering to the SRP means each service represents a specific business capability or domain. This allows development teams to focus on a particular business function, fostering faster development cycles and cleaner, more maintainable code.

The SRP is crucial for realizing the benefits of a microservices architecture. Features of a system designed with the SRP in mind include: each microservice focusing on one business capability; services organized around business domains rather than technical concerns (e.g., databases, messaging systems); clear boundaries and responsibilities between services; the enablement of autonomous development and deployment by independent teams; and the promotion of high cohesion within individual services. These features lead to significant advantages.
Pros:
- Simplified development and maintenance: Smaller, focused services are easier to understand and modify, leading to faster development cycles and reduced maintenance overhead.
- Improved understandability: Each service has a clear purpose, making it easier for developers to grasp its functionality and role within the larger system.
- Independent team ownership: Teams can own and manage individual services, fostering autonomy and accelerating development.
- Focused testing and deployment: Smaller codebases facilitate more targeted testing and enable faster, more frequent deployments.
- Reduced impact of changes: Changes to one service are less likely to impact others, minimizing the risk of cascading failures.
Cons:
- Challenging boundary definition: Deciding the right granularity for services can be difficult, requiring careful consideration of business capabilities and domain boundaries.
- Potential for duplication: If boundaries aren't clearly defined, some functionality might be duplicated across multiple services.
- Over-granularity: Over-application of the SRP can lead to an excessive number of very small services, increasing operational complexity.
- Increased operational complexity: Managing a larger number of services can be more complex than managing a monolithic application.
Examples of Successful Implementation:
- Amazon: Their e-commerce platform leverages separate services for managing the product catalog, pricing, inventory, recommendations, and user reviews.
- Netflix: Their architecture separates services for streaming, recommendations, and user management, enabling independent scaling and evolution of each component.
- Uber: Trip management is handled by a separate service from payment processing, allowing each to evolve and scale independently to meet demand.
Tips for Applying the SRP in Microservices Design:
- Domain-Driven Design (DDD): Use DDD to identify bounded contexts, which can serve as a basis for defining service boundaries.
- Focus on Business Capabilities: Define service boundaries based on distinct business capabilities rather than technical considerations.
- Event Storming: Use event storming workshops to understand the relationships between different domains and identify potential service boundaries.
- Iterative Refinement: Be prepared to refactor service boundaries as you gain more experience and understanding of the system.
- Conway's Law: Consider Conway's Law, which states that organizations design systems that mirror their communication structures. Organize teams around services to promote autonomy and ownership.
The Single Responsibility Principle is fundamental to successful microservices design. By adhering to this principle, development teams can create systems that are more scalable, resilient, and easier to maintain. It empowers teams to work independently, release features more quickly, and adapt to changing business requirements with greater agility. For anyone building a microservices architecture, understanding and applying the SRP is essential.
2. Decentralized Data Management
Decentralized Data Management is a cornerstone of effective microservices design principles. It fundamentally shifts how data is handled within a microservices architecture, moving away from a monolithic, shared database to a model where each microservice owns its own data store. This empowers individual services with autonomy and flexibility, contributing significantly to the overall resilience and scalability of the application.
How it Works:
In a decentralized data management model, each microservice interacts with its dedicated database. This means Service A might use a relational database like PostgreSQL, while Service B, with different data needs, could opt for a NoSQL document database like MongoDB. This approach, known as polyglot persistence, allows each service to select the data store that best suits its specific requirements regarding data structure, query patterns, and performance characteristics. Accessing data from another service is done exclusively through APIs, preventing tight coupling and dependencies at the database level.
Why Decentralized Data Management Matters in Microservices:
This principle is crucial for several reasons. It eliminates the database as a single point of failure, a critical vulnerability in monolithic applications. If one service's database experiences downtime, it won't impact other services, preserving the overall application's functionality. This isolation also reduces the ripple effect of schema changes. Modifying the database schema for one service doesn't necessitate changes to other services, facilitating independent evolution and faster development cycles.
Features and Benefits:
- Each Service Owns its Data Store: Provides complete control over data models and storage technologies.
- Polyglot Persistence: Enables choosing the optimal database technology for each service's specific needs.
- Data Accessed via API: Promotes loose coupling and isolates services from database implementation details.
- Database Schema Changes Limited to a Single Service: Reduces the impact of schema modifications and facilitates independent deployments.
- Data Consistency Maintained through Events and Eventual Consistency: Supports asynchronous communication and loose coupling for improved resilience.
Pros:
- Eliminates database as a single point of failure.
- Enables selection of the optimal database technology for each service.
- Reduces impact of schema changes.
- Improves scalability by distributing data load.
- Supports independent service evolution.
Cons:
- Increased complexity in maintaining data consistency across services.
- Distributed transactions are challenging.
- Requires implementing the saga pattern for multi-service operations.
- Can lead to data duplication.
- More complex queries across service boundaries.
Examples of Successful Implementation:
Several tech giants leverage decentralized data management:
- Amazon: Utilizes a diverse range of databases tailored to the specific needs of its numerous microservices.
- Netflix: Employs Cassandra for its high availability and scalability, crucial for its streaming services.
- Uber: Uses a combination of MySQL, Redis, and custom storage solutions across different services to optimize for various data access patterns.
- Spotify: Leverages PostgreSQL, Cassandra, and other databases to manage its vast music library and user data.
Actionable Tips for Implementation:
- Implement the Database-per-Service Pattern: Strictly adhere to the principle of one database per microservice.
- Use Asynchronous Messaging for Cross-Service Data Consistency: Leverage message queues like Kafka or RabbitMQ to propagate data changes between services.
- Consider CQRS (Command Query Responsibility Segregation): Separate read and write models to optimize data access patterns.
- Implement Event Sourcing to Track State Changes: Maintain a log of all events that modify data, allowing for reconstructing past states and auditing.
- Use Data Replication Sparingly for Read-Only Copies: Create read replicas for frequently accessed data to improve performance, but be mindful of consistency issues.
- Design with Eventual Consistency in Mind: Accept that data consistency might not be immediate across all services and design accordingly.
Popularized By:
The concept of decentralized data management has been championed by influential figures in the software development community, including Martin Fowler through his writings on microservices, Chris Richardson and his "Database per Service" pattern, and Greg Young through his work on event sourcing.
Decentralized data management, though complex, is essential for building robust and scalable microservices architectures. By embracing this principle, developers can unlock the true potential of microservices and create applications that are resilient, adaptable, and prepared for future growth. It truly earns its place as a core microservices design principle.
3. API-First Design
API-First Design is a critical microservices design principle that prioritizes the design of service interfaces (APIs) before the implementation of the services themselves. This approach treats APIs as first-class citizens, establishing clear contracts between services and ensuring that communication pathways are well-defined from the outset. In a microservices architecture, where numerous independent services interact, well-designed APIs are essential for maintaining order, promoting loose coupling, and facilitating seamless communication between services and client applications.

API-First Design employs a contract-first development approach. This means that before a single line of service code is written, the API's structure, functionalities, data formats, and error handling are meticulously defined using standards like OpenAPI/Swagger. This specification serves as a blueprint for all subsequent development, ensuring that all services adhere to the agreed-upon interface. Versioning is another crucial aspect, allowing APIs to evolve while maintaining backward compatibility and minimizing disruption for existing consumers.
This approach earns its place among core microservices design principles due to its significant benefits in managing the complexities of distributed systems. By clearly defining the interaction points between services, API-First Design promotes loose coupling, meaning that services can be developed and deployed independently without affecting each other as long as they adhere to the API contract. This fosters greater agility, allowing teams to work in parallel and iterate faster.
Features of API-First Design:
- APIs designed before implementation begins
- Contract-first development approach
- Clear interface definitions using standards like OpenAPI/Swagger
- Versioned APIs to manage evolution
- Focus on backward compatibility
Pros:
- Enables parallel development: Teams can work concurrently on different services, accelerating development cycles.
- Provides clear contracts between teams: Reduces miscommunication and integration issues by establishing a shared understanding of service interactions.
- Facilitates client development: Clear API specifications enable client application development to proceed alongside service implementation.
- Makes service boundaries explicit: Defines clear responsibilities for each service.
- Reduces integration issues: By adhering to the API contract, integration becomes smoother and more predictable.
Cons:
- Initial API design can be time-consuming: Requires careful planning and consideration of various use cases.
- May require updates: API specifications might need adjustments as implementation progresses and new requirements emerge.
- Requires discipline: Maintaining accurate and up-to-date API documentation is crucial.
- Versioning can be complex: Requires careful planning to avoid breaking changes for existing clients.
Examples of Successful Implementation:
- Twitter: Uses an API-first approach for its platform, allowing third-party developers to build applications that integrate with Twitter's services.
- Stripe: Known for its comprehensive API documentation and robust versioning practices.
- Twilio: Emphasizes developer-centric API design, making it easy for developers to integrate communication functionalities into their applications.
- Salesforce: Leverages an API-first strategy to support its extensive ecosystem of applications and integrations.
Tips for Implementing API-First Design:
- Use OpenAPI (Swagger): For documenting and designing REST APIs.
- Consider gRPC or GraphQL: For specific use cases requiring high performance or flexible data retrieval.
- Implement API gateways: To manage cross-cutting concerns like authentication, authorization, and rate limiting.
- Apply semantic versioning: To manage API evolution and communicate changes effectively.
- Create developer portals: With interactive documentation and code examples to facilitate client development.
- Design with backward compatibility in mind: Minimize breaking changes to avoid disrupting existing client applications.
- Use contract testing: To validate that services adhere to the defined API contract.
API-First Design is particularly valuable for independent developers, startup founders, freelance agencies, product managers, and technical leads working on microservices projects. By prioritizing API design, these individuals and teams can streamline development processes, improve collaboration, and build more robust and scalable systems. For AI enthusiasts and prototypers, a well-defined API can facilitate easier integration with AI models and services, accelerating experimentation and development.
4. Autonomous Teams: A Cornerstone of Microservices Design Principles
Autonomous teams are a crucial element of effective microservices architecture, representing a significant shift from traditional, layered development structures. This principle advocates for organizing teams around specific business capabilities or services, rather than technical functions (like database, backend, frontend). Each team takes end-to-end ownership of one or more services – covering design, development, testing, deployment, and maintenance. This approach strongly aligns with Conway's Law, which posits that the architecture of a system will inevitably mirror the communication structure of the organization building it. By empowering autonomous teams, organizations can foster faster development cycles, improved scalability, and greater resilience. This makes it a core microservices design principle and essential for any team or individual venturing into the world of microservices.
How Autonomous Teams Work within Microservices Architecture:
In a microservices environment built around autonomous teams, each team functions as a mini-startup. They are responsible for a specific service or set of related services that contribute to a larger business capability. This means a team might own everything related to, for example, the "user authentication" service or the "product catalog" service. This full ownership model empowers teams to make independent decisions about technology choices, implementation details, and deployment schedules without requiring excessive coordination with other teams. This decentralized decision-making fosters faster development cycles and allows teams to rapidly adapt to changing business requirements.
Features of Autonomous Teams:
- Organization around Business Capabilities: Teams are structured around specific business functions rather than technical silos.
- End-to-End Ownership: Each team is fully responsible for all aspects of their service(s), from inception to maintenance.
- Cross-Functional Composition: Teams possess a diverse skillset, including development, testing, operations, and sometimes even product management.
- Decentralized Decision-Making: Teams are empowered to make independent decisions regarding their services.
- Technology Choice Autonomy: Teams can choose the most appropriate technologies for their specific service.
- Independent Deployment Pipelines: Each team manages its own continuous integration and continuous delivery (CI/CD) pipelines.
Benefits of Implementing Autonomous Teams (Pros):
- Faster Delivery and Time-to-Market: Independent deployment pipelines and reduced coordination overhead enable quicker releases.
- Reduced Coordination Overhead: Less inter-team dependency streamlines development and minimizes bottlenecks.
- Increased Team Motivation and Ownership: Owning the entire lifecycle of a service fosters a sense of pride and responsibility.
- Better Alignment with Business Domains: Teams become specialists in their specific business area.
- Enhanced Scalability: Organizations can scale more effectively by adding new teams and services as needed.
- Improved Resilience: Isolation of services and independent teams limits the impact of failures and allows for faster recovery.
Challenges of Implementing Autonomous Teams (Cons):
- Potential for Technology Fragmentation: Independent technology choices can lead to a heterogeneous technology landscape.
- Duplication of Effort: Different teams might inadvertently reinvent the wheel by developing similar functionalities.
- Maintaining Consistent Practices: Ensuring consistent coding standards, testing practices, and deployment processes can be challenging.
- Higher Skill Requirements: Team members need to be proficient in multiple areas, potentially requiring upskilling.
- Cultural Shift: Adopting autonomous teams may require a significant cultural shift, especially in traditional organizations.
Examples of Successful Implementations:
- Amazon's "Two-Pizza Teams": Small, focused teams that can be fed with two pizzas, emphasizing efficient communication and collaboration.
- Spotify's Squad Model: Cross-functional teams organized around specific product features or services, promoting autonomy and agility.
- Netflix's Freedom and Responsibility Culture: Empowering teams with the freedom to make decisions and holding them accountable for the outcomes.
- Google's Small, Focused Groups: Encouraging small, independent teams to drive innovation and rapid development.
Actionable Tips for Implementing Autonomous Teams:
- Keep Teams Small (5-9 People): Smaller teams promote effective communication and collaboration.
- Ensure Cross-Functional Skills: Equip teams with all the necessary skills to develop, test, deploy, and maintain their services.
- Implement DevOps Practices: Foster a DevOps culture within each team to streamline development and operations.
- Use an Internal Open Source Model: Encourage sharing of code and best practices between teams.
- Establish Communities of Practice: Facilitate cross-team communication and knowledge sharing through communities of practice.
- Create Clear Service Ownership Documentation: Maintain clear documentation outlining the ownership and responsibilities of each team.
- Balance Autonomy with Governance: While promoting autonomy, establish necessary governance to ensure consistency and alignment with overall organizational goals.
By embracing the autonomous teams principle, organizations building microservices can achieve greater agility, scalability, and resilience. While challenges exist, the benefits significantly outweigh the drawbacks, making it a fundamental principle for successful microservices design. It's not just about dividing work; it's about empowering teams to own their domains and drive innovation within the larger ecosystem.
5. Infrastructure Automation
Infrastructure Automation is a crucial principle in microservices design principles that involves automating the provisioning, configuration, and deployment of the infrastructure required to run your services. This encompasses everything from the underlying servers and networking to the databases and load balancers. By treating infrastructure as code (IaC), embracing continuous integration/continuous deployment (CI/CD), and implementing automated testing, you ensure reliable and repeatable deployments. In a microservices environment, potentially dealing with hundreds of interconnected services, manual processes become unsustainable. Automation is no longer a luxury but an essential requirement for efficiency, reliability, and scalability.

This principle is essential for several reasons. First, it drastically reduces the risk of human error during deployments, a common problem in complex manual processes. Second, it enables faster release cycles, allowing you to bring new features to market more quickly. Third, it ensures consistent environments across development, testing, and production, minimizing unexpected behavior caused by environmental discrepancies. This consistency is especially valuable in a microservices architecture where different teams manage different services.
Infrastructure automation offers a wealth of features designed to streamline operations:
- Infrastructure as Code (IaC): Tools like Terraform and AWS CloudFormation allow you to define and manage your infrastructure in code, enabling version control, automated provisioning, and easy replication.
- Automated CI/CD Pipelines: Automate the entire software delivery process, from code commit to deployment, with tools like Jenkins, GitLab CI, and GitHub Actions.
- Containerization: Package your microservices and their dependencies into containers (e.g., using Docker) for consistent environments across different platforms.
- Orchestration Platforms: Manage and scale your containerized microservices using platforms like Kubernetes.
- Automated Testing: Implement automated testing at all levels—unit, integration, and end-to-end—to catch bugs early and ensure quality.
- Blue/Green Deployments and Canary Releases: Minimize downtime and risk during deployments by gradually rolling out new versions of your services.
- Self-Healing Systems: Design systems that automatically detect and recover from failures, ensuring high availability.
While the benefits are significant, there are also challenges:
Pros:
- Reduced manual errors in deployments
- Faster release cycles and time-to-market
- Consistent environments across development and production
- Improved disaster recovery capabilities
- Enables frequent, small updates with lower risk
- Better resource utilization
Cons:
- Initial setup requires significant investment
- Learning curve for new tools and practices
- Requires culture shift in traditional organizations
- Tool proliferation can increase complexity
For improved performance and security of your deployed microservices, consider integrating Cloudflare. You can find a helpful guide here: Boost Your SME's Web Performance and Security with Cloudflare Integration
Examples of Successful Implementation:
- Netflix: Uses Spinnaker for multi-cloud continuous delivery, demonstrating the power of sophisticated automation for complex deployments.
- Amazon: Relies heavily on AWS CloudFormation for infrastructure provisioning, showcasing the scalability of IaC.
- Google: Developed Kubernetes, the leading container orchestration platform, highlighting the importance of container management in microservices.
- Etsy: Known for its approach to automated deployment with feature flags, demonstrating how to decouple deployment from release for greater control.
Tips for Implementation:
- Start with containerization using Docker.
- Use Kubernetes or a similar platform for orchestration.
- Implement IaC with Terraform, CloudFormation, or similar tools.
- Automate testing at unit, integration, and end-to-end levels.
- Implement observability from the beginning.
- Use feature flags to decouple deployment from release.
- Design for zero-downtime deployments.
- Practice chaos engineering to verify resilience.
Infrastructure automation is not just a best practice; it's a necessity for successful microservices implementations. By embracing this principle, you can build and deploy reliable, scalable, and resilient systems that can adapt to the ever-changing demands of the modern software landscape. Pioneered by companies like Netflix, HashiCorp, Docker, Google, and thought leaders like Jez Humble and David Farley, these principles are now essential for anyone working with microservices.
6. Resilience and Fault Tolerance
Resilience and fault tolerance are critical microservices design principles, ensuring that your application can gracefully handle failures without a complete system outage. In a distributed system like a microservices architecture, individual service failures are inevitable. This principle focuses on building systems that can withstand these failures, degrade gracefully, and continue operating, even with reduced functionality, when dependencies are unavailable. This involves implementing patterns like circuit breakers, bulkheads, timeouts, and retry mechanisms to isolate failures and prevent cascading effects.
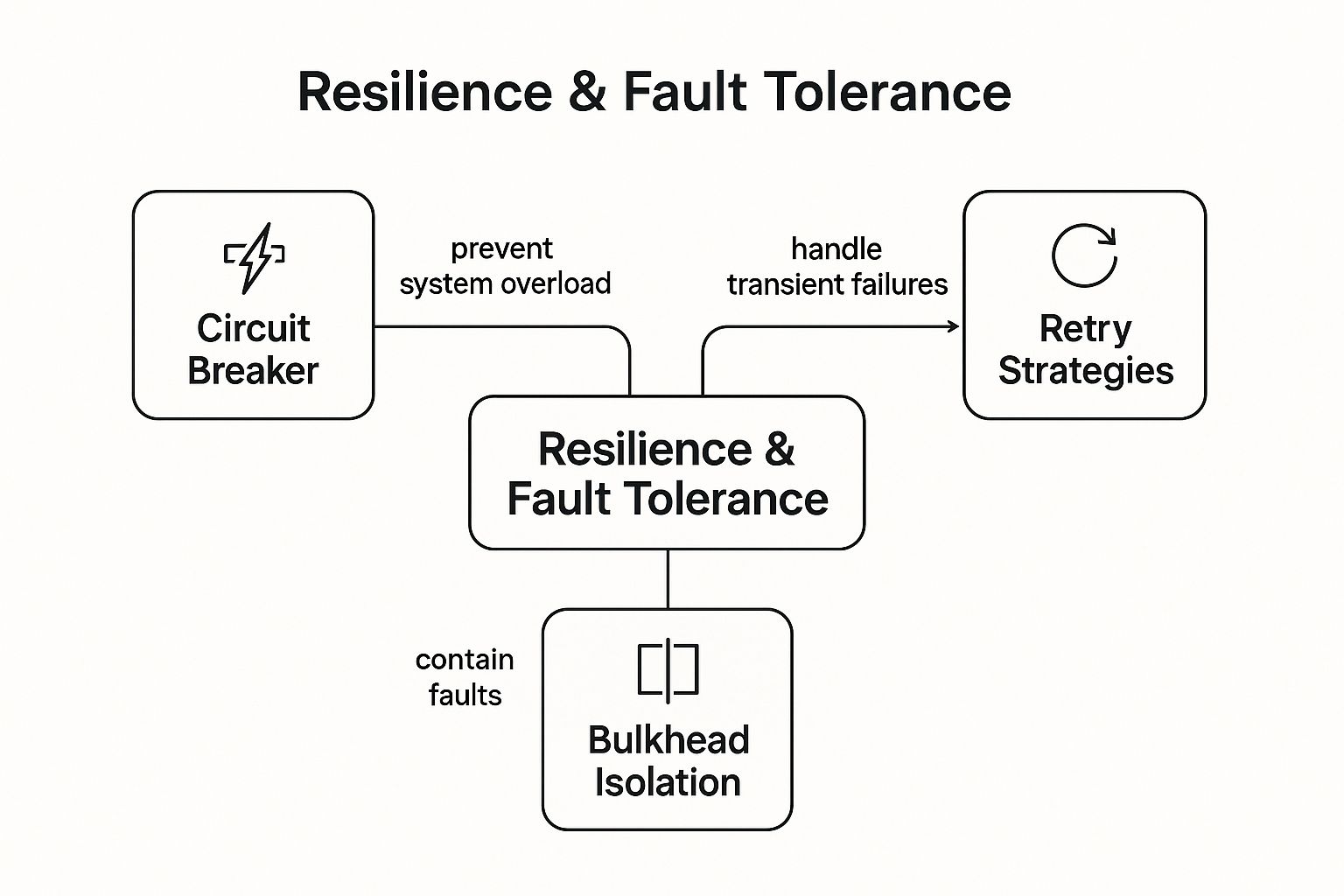
The infographic visualizes the core concept of Resilience and Fault Tolerance, with related strategies branching out. The central idea is to maintain system functionality despite failures. Key strategies include preventing cascading failures through circuit breakers, isolating failures using bulkheads, employing retry mechanisms and timeouts, and ensuring graceful degradation with fallback mechanisms. The infographic emphasizes the interconnectedness of these strategies in achieving overall system resilience. As the visualization shows, each of these strategies contributes to the overall goal of maintaining service availability and minimizing the impact of failures.
This principle is crucial for microservices because the distributed nature of the architecture increases the points of failure. By designing for resilience, you ensure that a single failing service doesn't bring down the entire application. This directly contributes to improved user experience and higher availability.
Features contributing to resilience and fault tolerance include:
- Circuit Breaker Pattern: Prevents repeated calls to a failing service, allowing it time to recover.
- Bulkhead Pattern: Isolates failures to specific parts of the application, preventing widespread outages.
- Timeout Mechanisms: Prevent indefinite blocking of threads waiting for responses from failing services.
- Retry Strategies: Enable automatic retries with exponential backoff to handle transient failures.
- Fallback Mechanisms: Provide alternative responses or functionalities when a service is unavailable.
- Health Checks and Self-Healing: Monitor service health and automatically restart or redeploy failing instances.
- Asynchronous Communication: Decouples services, reducing the impact of dependencies on availability.
Pros:
- Prevents cascading failures across the system.
- Improves overall system availability and reduces MTTR (Mean Time To Recovery).
- Enables partial functionality even during failures, enhancing user experience.
- Supports high-availability requirements.
Cons:
- Adds complexity to service implementation and requires more sophisticated testing.
- Debugging failure scenarios becomes more complex.
- May require additional infrastructure for monitoring and alerting.
- Can potentially increase development time.
Examples of Successful Implementation:
- Netflix Hystrix: A library providing circuit breaker and fault tolerance functionalities.
- Amazon's Architecture: Highly available systems designed to handle component failures seamlessly.
- Google SRE Practices: Site Reliability Engineering emphasizes building and maintaining resilient services.
- Spotify's Approach: Extensive use of circuit breakers to manage dependencies.
Tips for Implementation:
- Utilize libraries like Hystrix, Resilience4j, or Polly for circuit breaker implementation.
- Design with failure in mind – assume services will fail and plan accordingly.
- Implement health checks for early failure detection and automated recovery.
- Use chaos engineering tools like Chaos Monkey for resilience testing.
- Set up comprehensive monitoring and alerting for failures.
- Define suitable timeouts for all service calls.
- Consider using service meshes like Istio or Linkerd for built-in resilience features.
When and Why to Use This Approach:
Resilience and fault tolerance are essential for any microservices architecture. They are particularly crucial when:
- Building mission-critical applications where downtime is unacceptable.
- Dealing with complex systems with multiple dependencies.
- Operating in distributed environments prone to network issues and service failures.
- Aiming for high availability and a robust user experience.
By prioritizing resilience and fault tolerance as a core design principle, you build microservices that are robust, reliable, and capable of weathering the inevitable storms of distributed systems. This directly contributes to the success of your application and a positive user experience. These principles are fundamental for anyone building microservices, from individual developers to large enterprises, ensuring that their applications remain functional and responsive even in the face of adversity. This makes it a key principle within the broader context of microservices design.
7. Design for Observability
In the intricate world of microservices, where numerous independent services interact to form a complete system, understanding the internal workings of each component and their interplay becomes paramount. This is where the principle of "Design for Observability" shines. This crucial microservices design principle emphasizes building services that openly expose their internal state and behavior, enabling efficient monitoring, troubleshooting, and ultimately, a deeper understanding of the system's performance and health. Ignoring this principle can lead to a debugging nightmare when issues inevitably arise in production.
Observability goes beyond simple monitoring. While monitoring tells you what is wrong, observability empowers you to understand why. It achieves this through three core pillars:
-
Logging: Comprehensive logging provides a detailed record of events occurring within a service. This includes errors, warnings, informational messages, and debug logs. Centralized logging, coupled with correlation IDs, allows you to trace a request's journey across multiple services.
-
Metrics: Metrics quantify the behavior of your services, capturing data points like request latency, error rates, CPU usage, and memory consumption. Real-time metrics collection and visualization provide valuable insights into system performance and resource utilization.
-
Distributed Tracing: In a microservices architecture, a single user request often traverses multiple services. Distributed tracing allows you to follow this request across the entire system, pinpointing performance bottlenecks and identifying the root cause of latency issues.
By incorporating these three pillars from the design phase, you build a system that is inherently easier to understand and manage.
Why Observability is Essential for Microservices
In a monolithic application, debugging is relatively straightforward. You can typically attach a debugger and step through the code. Microservices, however, introduce complexity due to their distributed nature. Design for Observability addresses this complexity head-on, offering several key benefits:
Pros:
- Faster Troubleshooting and Reduced MTTR (Mean Time To Resolution): Quickly identify the source of problems and resolve them efficiently.
- Better Understanding of System Behavior in Production: Gain insights into how your services interact and perform under real-world conditions.
- Ability to Identify Performance Bottlenecks: Pinpoint services or code segments that are slowing down the system.
- Improved Capacity Planning Based on Metrics: Make informed decisions about scaling your infrastructure based on usage patterns.
- Enhanced Ability to Detect and Address Issues Before They Affect Users: Proactive monitoring and alerting help prevent outages and maintain a positive user experience.
- Easier Debugging of Distributed Transactions: Trace requests across multiple services to understand the flow of data and identify errors.
Cons:
- Additional Overhead in Service Implementation: Instrumenting your code for observability requires some effort.
- Increased Data Storage Requirements for Logs and Metrics: Storing and managing observability data can consume significant storage space.
- Potential Performance Impact from Instrumentation: Overly aggressive instrumentation can impact service performance.
- Requires Additional Infrastructure for Monitoring Tools: Setting up and maintaining monitoring tools adds complexity.
- May Need Specialized Skills for Advanced Monitoring: Utilizing advanced monitoring techniques may require specialized training.
Examples of Successful Implementation:
- Google's Dapper: The pioneering distributed tracing system that laid the foundation for many modern tracing tools.
- Netflix's Comprehensive Monitoring and Alerting Infrastructure: Netflix's robust system allows them to manage their vast streaming platform.
- Uber's Observability Stack with Jaeger for Tracing: Uber utilizes Jaeger for tracing requests across their complex ride-sharing platform.
- Twitter's Distributed Systems Monitoring Approach: Twitter's sophisticated monitoring helps them manage the immense volume of tweets and user interactions.
Actionable Tips for Implementing Observability:
- Implement correlation IDs across all service calls: This allows you to trace a request across multiple services.
- Use OpenTelemetry for standardized instrumentation: OpenTelemetry provides a vendor-neutral framework for collecting telemetry data.
- Adopt structured logging with consistent formats: This makes it easier to parse and analyze logs.
- Deploy an ELK (Elasticsearch, Logstash, Kibana) or similar stack for log management: ELK provides a powerful and scalable solution for log aggregation and visualization.
- Use Prometheus and Grafana for metrics collection and visualization: Prometheus and Grafana are popular open-source tools for metrics monitoring.
- Implement distributed tracing with Jaeger or Zipkin: These tools provide insights into the flow of requests across your services.
- Create dashboards for key business and technical metrics: Visualize important data points to gain a quick overview of system health.
- Define clear alerting thresholds and escalation policies: Ensure that you are notified of critical issues and have a plan for addressing them.
By prioritizing Design for Observability, you equip yourself with the tools and insights needed to navigate the complexities of microservices architecture, ensuring system reliability, performance, and ultimately, user satisfaction. This principle is not merely a best practice; it's a necessity for building and operating successful microservices systems.
7 Principles of Microservices Design Comparison
| Principle | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Single Responsibility Principle | Medium - defining clear boundaries is challenging | Moderate - requires domain knowledge and domain-driven design | High cohesion within services, autonomous deployment | Business domain-driven microservices needing clear separation | Simplifies maintenance, enables independent deployment, clear service ownership |
| Decentralized Data Management | High - managing data consistency is complex | High - multiple databases and data sync mechanisms | Improved scalability, independent data evolution, reduced failure impact | Services with distinct data needs, polyglot persistence | Eliminates single points of failure, optimal DB choice, supports independent evolution |
| API-First Design | Medium - upfront API contract design effort | Moderate - tools and documentation maintenance | Clear communication contracts, reduced integration issues | Multi-team environments requiring clear interface contracts | Enables parallel development, reduces integration errors, explicit service boundaries |
| Autonomous Teams | Medium to High - organizational shift and coordination needed | Moderate to High - cross-functional skillsets and DevOps capabilities | Faster delivery, improved team motivation, aligned with business domains | Organizations scaling teams around services and capabilities | Increased speed, reduced coordination, ownership boosts motivation |
| Infrastructure Automation | High - significant initial setup and tooling learning curve | High - CI/CD pipelines, container orchestration, IaC tools | Consistent environments, faster reliable deployments | Complex microservices environments with frequent releases | Reduces manual errors, speeds releases, improves disaster recovery |
| Resilience and Fault Tolerance | High - complex failure handling patterns | Moderate - monitoring and fault-tolerant infrastructure | Increased availability, graceful degradation, reduced downtime | Systems requiring high availability and fault tolerance | Prevents cascading failures, improves recovery, enhances user experience |
| Design for Observability | Medium - instrumentation and monitoring setup | Moderate to High - storage and monitoring infrastructure | Faster troubleshooting, better insights, anomaly detection | Distributed systems needing robust monitoring and debugging | Reduced MTTR, strong system insights, detects bottlenecks early |
Level Up Your Microservices Architecture
Mastering microservices design principles is crucial for building modern, scalable, and resilient applications. Throughout this article, we've explored seven key principles—from the Single Responsibility Principle and Decentralized Data Management to Design for Observability and Infrastructure Automation—that form the foundation of a successful microservices architecture. By adhering to these principles, you empower your teams to work autonomously, iterate quickly, and deliver value faster. Remember, the true power of embracing these microservices design principles lies in their combined effect: increased agility, improved maintainability, and enhanced resilience, enabling you to adapt and respond to ever-changing market demands. These benefits are particularly critical for AI enthusiasts, startup founders, and freelance agencies alike, allowing them to rapidly prototype, scale innovative solutions, and stay ahead of the competition.
Successfully implementing these concepts can be challenging, but the rewards are well worth the effort. By building systems designed for change, you create a future-proof foundation for your projects. A well-designed microservices architecture, guided by the principles we've covered, unlocks the potential for unparalleled scalability and resilience, enabling your applications to handle increasing complexity and evolving business needs.
Ready to streamline your microservices journey and put these principles into practice? AnotherWrapper provides pre-built components, integrations, and best practices aligned with these core microservices design principles, allowing you to accelerate development and focus on delivering business value. Explore AnotherWrapper today and discover how it can help you build robust and scalable microservices architectures: AnotherWrapper
Stay ahead of the curve
Weekly insights on AI tools, comparisons, and developer strategies.

Fekri
Building tools for the next generation of AI-powered startups. Sharing what I learn along the way.
Related
Tags
Continue reading
You might also enjoy

Agile Release Management: Your Complete Guide to Success
Master agile release management with proven strategies that work. Learn from successful teams who've transformed their software delivery process.

AI Model Deployment: Expert Strategies to Deploy Successfully
Learn essential AI model deployment techniques from industry experts. Discover proven methods to deploy your AI models efficiently and confidently.

AI MVP Development: Build Smarter & Launch Faster
Learn top strategies for AI MVP development to speed up your product launch and outperform competitors. Start building smarter today!